
Artificial Intelligence
Expert View
AI Deployment: Wie lässt sich AI am besten betreiben?
Diese Frage stellen sich aktuell viele Unternehmen. Denn für den Erfolg von AI ist das Deployment entscheidend. Nur wer die Überführung von Large Language Modellen (kurz: LLMs) und generative AI von der Pilotphase in den produktiven Betrieb meistert, kann tatsächlich von AI profitieren. Dabei kann das Deployment ganz unterschiedliche Dimensionen annehmen. Von kleinen Testszenarien bis hin zu großflächigen Rollouts. Doch welche Deployment-Möglichkeiten gibt es? Und wie können Unternehmen die Methode auswählen, die ihre Anforderungen am besten erfüllen? Diese und weitere Fragen beantwortet CANCOM-Expertin Eva Dölle im Gastbeitrag.
10. Februar 2026
|

Bild: © M.Gierczyk/stock.adobe.com
Der Bereich AI Deployment spielt für Unternehmen eine zentrale Rolle. Eine gezielte Umsetzung stellt sicher, dass AI-Initiativen erfolgreich aus der Pilotphase in den produktiven Betrieb überführt werden – und der durch AI gewünschte Mehrwert tatsächlich entsteht. Wie CANCOM-Expertin Eva Dölle im Gastbeitrag beschreibt, ist die Umsetzung allerdings anspruchsvoll. So müssen Unternehmen festlegen, welche Umgebungen (On-Premises, Cloud, Hybrid oder Edge) und welche Methoden (Bare Metal, Virtualisierung oder Containerisierung) sich am besten für ihr AI Deployment eignen. CANCOM begleitet Unternehmen umfassend bei dieser Entscheidungsfindung – und übernimmt auf Wunsch auf die Einführung entsprechender Lösungen. Hier können Sie mit den CANCOM-Experten in Kontakt treten.
Dieser Text wurde mithilfe von AI erstellt und redaktionell überprüft.
Generative AI ist längst in Unternehmen angekommen. Laut der Studie „Generative KI in der deutschen Wirtschaft 2025“ von KPMG bewerten 91 Prozent die Technologie als wichtig für ihr Geschäftsmodell und die künftige Wertschöpfung. 82 Prozent planen entsprechende Investitionen in naher Zukunft.
Damit Unternehmen in der Praxis von AI profitieren, müssen sie verschiedene Aspekte beachten. Dazu gehört besonders der Bereich AI Deployment, also der Übergang von AI-Projekten von der Pilotphase in den produktiven Betrieb. Dieser Übergang birgt jedoch Herausforderungen. Wie die Studie „The GenAI Divide: State of AI in Business 2025“ aufzeigt, scheitern aktuell 95 Prozent aller AI-Projekte bereits in der Pilotphase (CANCOM.info berichtete).
Um das zu verhindern und einen wesentlichen Schritt in Richtung erfolgreicher AI-Projekte zu gehen, müssen Firmen das Thema AI Deployment gut durchdenken. Im Folgenden erfahren Sie, welche Möglichkeiten sie haben.
Lokales AI Deployment: AI im eigenen Rechenzentrum
Grundsätzlich können Unternehmen flexibel entscheiden, in welcher Umgebung sie das AI Deployment umsetzen möchten. Dies ist sowohl im eigenen Rechenzentrum, in der Cloud als auch am Edge möglich. Auch hybride Szenarien sind realisierbar.
Allerdings lässt sich heute eine klare Tendenz feststellen. Immer mehr Unternehmen ziehen in Betracht, LLMs und generative AI lokal zu betreiben. Der eigene Betrieb ermöglicht deutlich niedrigere Kosten pro Token, insbesondere bei stabiler und wiederkehrender Inferenz-Last. Unter Inferenz versteht man den Prozess, bei dem eine bereits trainierte AI-Lösung neue Daten verarbeitet, um Vorhersagen oder Antworten zu generieren. Dazu ruft die Lösung das vorhandene Wissen aus den Trainingsdaten ab und wendet es auf neue Fragen an.
Zudem behalten Unternehmen mit lokalen AI Deployments die volle Souveränität und Kontrolle über ihre Daten. Dies ist besonders in regulierten Branchen ein zentraler Faktor. Dadurch lassen sich auch die Einhaltung strenger gesetzlicher Vorgaben, wie etwa der Datenschutzgrundverordnung (DSGVO) oder des EU AI Acts, deutlich einfacher sicherstellen,
Ein weiterer Vorteil ist die verlässliche Performance. Lokale AI Deployments unterliegen keinen Rate Limits (Begrenzung der Anfragen) externer Anbieter, keinem Throttling (Drosselung der Geschwindigkeit) und keiner externen API-Verfügbarkeit. Latenzen bleiben stabil und gut vorhersehbar, was besonders wichtig ist, wenn AI-Funktionen in bestehende operative Systeme eingebunden werden. Außerdem lassen sich per Retrieval Augmented Generation (RAG) interne Datenquellen direkt einbinden. So müssen sensible Inhalte keine externen Dienste durchlaufen. Das schafft nicht nur Sicherheit und Vertrauen, sondern auch eine technische Basis für unternehmensinterne Wikis.
Ein Beispiel für die Umsetzung eines solchen RAGs ist unser CANCOM Asisstant. Mit unserer Lösung können Unternehmen generative AI und LLMs bei Bedarf vollständig im eigenen Rechenzentrum betreiben. Auch der Betrieb in der Cloud oder in hybriden Umgebungen ist möglich.
Diese 3 Deployment-Methoden stehen zur Auswahl
Grundlegend gibt es 3 Deployment-Methoden. Die Wahl der Bereitstellung richtet sich danach, welche Strukturen bereits vorhanden sind:
- Bare Metal Deployment
- Virtualisiertes Deployment
- Containerisiertes Deployment
Dabei ist zu betonen, dass in der Praxis diese Modelle meist nicht strikt voneinander getrennt sind, sondern auch miteinander kombiniert werden. Dies trifft insbesondere auf die Containerisierung zu: Sie bildet eine zusätzliche Schicht auf Bare Metal oder virtualisierten Hosts. Entsprechend ist es nicht zwangsläufig nötig, sich zwischen virtuellen Maschinen und Containern zu entscheiden.
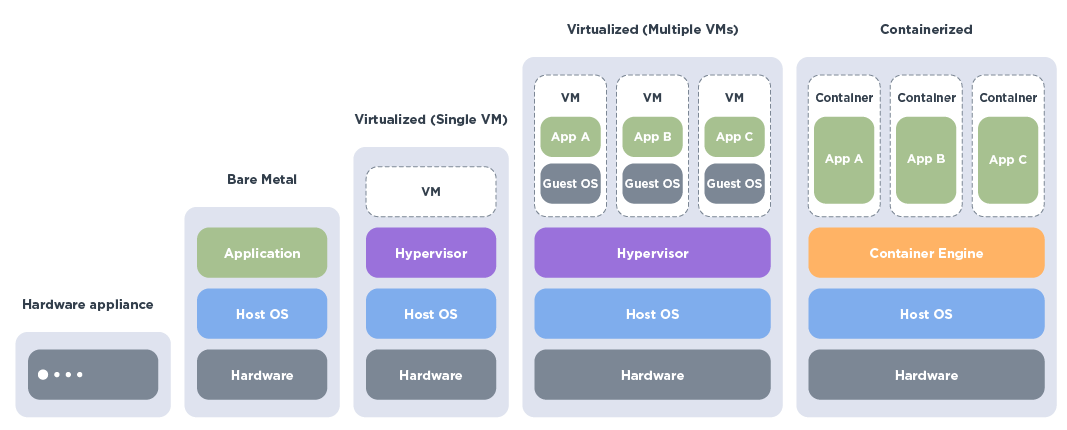
Die AI Deployment-Möglichkeiten in der Übersicht (Bild: © CANCOM).
1. Bare Metal Deployment
Beim Bare Metal Deployment läuft das AI-Modell unmittelbar auf der vorhandenen Hardware, ohne Virtualisierungsschicht dazwischen. Die Maschine steht damit exklusiv einem Workload zur Verfügung. Der Einstieg ist entsprechend unkompliziert: installieren, AI-Modell laden, loslegen. Werkzeuge wie Ollama / Open WebUI, LM Studio oder AnythingLLM erfreuen sich aktuell großer Beliebtheit bei dieser Form der Bereitstellung, weil diese Tools direkt mit der lokalen GPU arbeiten und keine zusätzliche Infrastruktur benötigen.
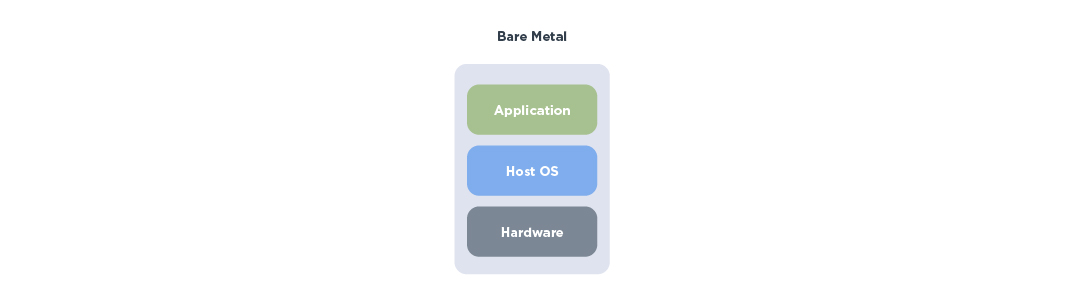
Bei Bare Metal läuft die Applikation direkt auf dem Host (Bild: © CANCOM).
Das macht Bare Metal ideal für Einzelanwender, Proof-of-Concepts oder Situationen, in denen ein AI-Modell schnell und ohne organisatorischen Aufwand lauffähig sein soll. Die Hardware wird vollständig ausgenutzt, da keine Zwischenebene Ressourcen verbraucht oder Scheduling-Entscheidungen trifft.
Die Nachteile zeigen sich jedoch im Team- oder Unternehmenskontext. Mehrere parallele Nutzer oder unterschiedliche AI-Modellversionen lassen sich nur schwer koordinieren, da jede Änderung manuell eingepflegt werden muss. Sicherheit, Updates, Monitoring und Protokollierung sind nicht zentralisiert und werden schnell unübersichtlich. Auch die Skalierung ist eingeschränkt, da jeder Server physisch für genau diesen Zweck betrieben wird und nicht flexibel in eine größere Umgebung eingebettet werden kann.
2. Virtualisiertes Deployment
Beim virtualisierten Deployment werden Rechenressourcen (z.B. CPU-/GPU-Leistung) zwischen verschiedenen virtuellen Maschinen (kurz: VMs) aufgeteilt. Um diesen Vorgang durchführen zu können, kommen sogenannte Hypervisoren zum Einsatz. Auf diesen läuft bzw. laufen dann die VM bzw. die VMs. Beispiele für bekannte Hypervisoren sind VMware vSphere, Citrix, Nutanix AHV oder Microsoft Hyper-V.
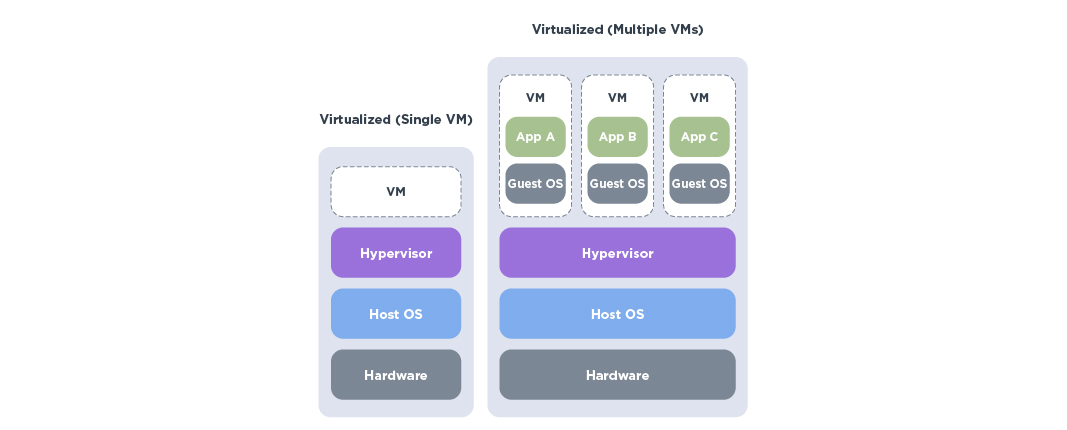
Der Hypervisor läuft auf dem Betriebssystem des Hosts und weist Ressourcen an eine oder mehrere VMs zu (Bild: © CANCOM).
Beim virtualisierten Deployment gibt es eine physische GPU, die in einem Server oder einer Workstation sitzt. Diese GPU kann entweder direkt an den Nutzer weitergereicht werden (GPU Passthrough) oder logisch / physisch unterteilt werden (vGPU oder Multi-Instance GPU). Damit können mehrere VMs gleichzeitig GPU-beschleunigte Workloads ausführen, ohne dass jede VM eine vollständige GPU benötigt.
In der Regel wird diese Technologie beim Aufbau einer Virtual Desktop Infrastructure (VDI) genutzt. Hierbei wird dem Nutzer über einen zentralen Server eine einzelne Anwendung oder eine komplette Desktop-Umgebung auf seinem Endgerät bereitgestellt. Ein weiteres klassisches Szenario ist die Nutzung im Rahmen grafisch anspruchsvoller Projekte. Hier beanspruchen Nutzer die zentralen GPU-Ressourcen über ihr lokales Device, die sie dann unter anderem für Rendering-Prozesse verwenden.
Der Vorteil eines virtualisierten Deployments liegt vor allem in der verbesserten Auslastung der GPU und der damit gesparten Kosten.
Diese Art des Deployments ist besonders dann die beste Wahl, wenn eine Gruppe von Nutzern einen flexiblen Zugang zu grafischen Ressourcen benötigt. Ein weiterer Mehrwert ergibt sich für Unternehmen, die bereits zuvor eine Virtualisierungsplattform im Einsatz hatten. In solchen Fällen lässt sich die Verwaltung der Grafikressourcen unkompliziert in die jeweilige Virtualisierungsplattform integrieren.
Dennoch birgt das virtualisierte Deployment auch Nachteile. Es werden spezielle Rechenzentrums-GPUs gebraucht, die bei den meisten Herstellern mit zusätzlichen Lizenzen im Abo-Modell verbunden sind. Weiterhin kommt es durch die Virtualisierungsschicht zu einem Overhead, der die Latenz beeinträchtigt. Außerdem kann es immer vorkommen, dass zu viele Nutzer auf die GPU zugreifen wollen (Überbuchung). Folglich kann es zu Leistungsschwankungen kommen, trotz Zuteilungsmechanismen des Hypervisors (sogenannte Scheduler).
Seite 1


